 Colin Harman is an Enterprise AI-focused engineer, leader, and writer. He has over two years’ experience in implementing LLM-based software solutions for large enterprises, and serves as the Head of Technology at Nesh. Colin specialises in troubleshooting the unique challenges posed by the interaction of generative AI with the enterprise environment.
Colin Harman is an Enterprise AI-focused engineer, leader, and writer. He has over two years’ experience in implementing LLM-based software solutions for large enterprises, and serves as the Head of Technology at Nesh. Colin specialises in troubleshooting the unique challenges posed by the interaction of generative AI with the enterprise environment.
In our latest post, Colin explores the challenges and risks enterprises encounter when implementing LLMs. The majority of advice on creating LLM projects, Colin argues, is aimed at start-ups. But mature enterprises have different data and requirements. Colin explains the key factors to consider for successful enterprise-level LLM integration:
Welcome to the age of Enterprise LLM Pilot Projects! A year after the launch of ChatGPT, enterprises are cautiously but enthusiastically progressing through their initial Large Language Model (LLM) projects, with the goal of demonstrating value and lighting the way for mass LLM adoption, use case proliferation and business impact.
Developing these solutions either within or for mature businesses is fundamentally different from startups developing solutions for consumers. Yet the vast majority of advice on LLM projects comes from a startup-to-consumer perspective, intentionally or not. The enterprise environment poses unique challenges and risks, and following startup-toconsumer guidance without regard for the differences could delay or even halt your project. But first, what does “enterprise” mean?
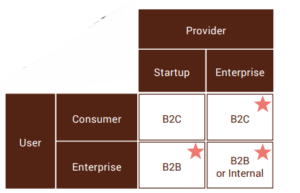
A simple provider-user matrix highlighting (*) where enterprise challenges and risks are involved. Note that a product provided to an enterprise user could end up with a consumer end-user, e.g. a chatbot provided to a financial services company for their clients.
There’s currently a strong but waning bias of LLM content toward the consumer-user and startup-provider portion of the provider-user matrix above. It’s largely driven by the speed to market and click-hungriness of VC-funded startups and independent creators.
Where, then, does the enterprise guidance that does exist come from, and can you trust it? This may surprise you, but very few enterprises have actually completed LLM projects. At this point, few entities like traditional consulting organisations are trading on actual experience, but instead use repackaged web content. There’s not been sufficient time for much enterprise experience to accumulate, let alone disseminate. There are plenty of exceptions, but the majority of future LLM experts from within the enterprise are still busy with their first projects, and the number of experienced startup providers for the enterprise is still limited.
As a B2B software vendor, I’ve had the privilege of developing and implementing LLM projects (the Startup/ Enterprise cell in the provider/user matrix above) for enterprises since 2021, and have overcome the set of unique challenges to complete multiple end-to-end implementations. In this article, I’ll share some of the most important dimensions I’ve observed in which the data involved in enterprise LLM projects differs from startup/consumer projects and what it means for your project. Use this to de-bias information coming from a startup/consumer perspective, inform yourself of risks, and build intuition around enterprise applications of LLMs.
Specifically, this post will focus on the data used for data-backed applications, which cover a majority of enterprise LLM use cases. Let’s move beyond the LLM parlour tricks of cleverly summarising an input or answering a question from its memory. The value that can be generated by allowing LLMs to operate over data is much greater than the value from interacting with standalone LLMs. To prove this, imagine an application that consists solely of LLM operations, taking user input and transforming it to produce an output. Now imagine that this same system can also access data stored outside the model: the capability is additive, and so is the value. This data could be anything: emails, client records, social graphs, code, documentation, call transcripts…
Almost always, the data comes into play through information retrieval – the application will look up relevant information and then interpret it using an LLM. This pattern is commonly known as RAG (RetrievalAugmented Generation). So, how does data differ between enterprise and startup/consumer applications, and what does that mean for your project?

Qualitative comparison of the data behind LLM applications in consumer and enterprise environments along several axes. It’s a cartoon, so relative sizes are approximate, and there are many exceptions.
Open-domain data refers to a wide array of topics that aren’t confined to any specific field or industry. This is the kind of data that consumer applications or publicfacing enterprise offerings deal with. On the other hand, closed-domain data is typically found in enterprise applications. This type of data is more specialised Enterprise Data and domain-specific and often includes terminology, acronyms, concepts, and relationships that are not present in open-domain data.
Pharmaceutical R&D documentation
Consumer Data
Failing to account for closed-domain data in your application could render it totally ineffective. Most commercial LLMs are trained on open-domain data and, without help, will simply fail to correctly interpret terms and topics they haven’t encountered in their training, likewise for the embedding models used in vector search. For example, many organisations have massive vocabularies of acronyms that are used as the primary handle for certain concepts, and without help, an LLM or retrieval system may be unable to relate the acronyms to the concepts they represent.
However, don’t be fooled into undertaking costly retraining projects if it’s not actually needed or there are simpler solutions! Many domains that seem closed are, in fact, open. For example, commercial LLMs have been trained on an immense amount of public financial data and intuitively understand it because, while finance is a particular domain, it is not a closed domain.
Unset Particular Domain ≠ Closed Domain
Even fields like medicine and law are heavily represented in public data, although subdomains often exhibit closed-domain properties (as with finance). Think twice before pursuing training projects or specialised models and evaluate whether they are truly needed. Expect more posts on how to assess the openness of your domain’s data.
In most cases of closed-domain data, you can get quite far by looking up synonyms or definitions of closeddomain terms and injecting them into your retrieval and generation systems. However, this requires you to have structured information around synonyms, relationships, or definitions, which may not be readily available. When possible, this pattern is often the best and simplest solution, and we’ll explore related techniques in future posts.
Unset Prefer bespoke systems to bespoke models
In summary:
Businesses tend to have more data than individual consumers. The simplest proof of this is that an enterprise is a collection of employees, clients/ consumers, and processes, all of which generate data, while a consumer is a population of one. Businesses also tend to undertake projects over longer spans of time than consumers, with a higher density of records within those spans. We’ll split the size dimension into 3:
Enterprise projects tend to occupy the “more data” side of each scale. The reason this matters is that, as the amount of data you retrieve grows, so does the likelihood that unhelpful records will be considered relevant, simply because there are more unhelpful records, or “noise.”
Unset More data causes less accurate retrieval
What’s more, certain types of data generate more noise than simple random data. Those are sometimes referred to as distractors, and we’ll see how they can occur in some of the subcategories.
Each part of an enterprise tends to deal with groups of things: employees, clients, products, and projects. Each unit in these groups can generate anywhere from a few to millions of records that your application may need to handle. Individual consumers may be one of those units and therefore represent a smaller slice of data. To understand your data along this dimension, ask: does it deal with a single entity or with many? Are those entities known, or even knowable?
Enterprise Data
Startup/Consumer Data
There reaches a point (that most enterprises’ datasets are well beyond), where it’s critical to limit the size of data your application operates over. Populationlevel data can easily push you past this limit. Even if your application contains an entire population’s data, you may be able to transform it into unit-level data at runtime by filtering on a target entity (client, product, project, etc), clearing the path for a simpler and more accurate retrieval system. However, in some projects, this can be impossible if your client wishes to provide an un-curated data dump of, for example, PC hard drives. There are several approaches to handling this:
When scoping the project, focus on a problem where the supporting data is well structured and able to be filtered down to a unit level.
If you aren’t successful with any of these, expect to spend a lot of effort reducing noise in your retrieval system. For both startup/consumer and enterprise applications, you should always seek to relieve the burden on the retrieval system by only searching through the relevant slice of data. This isn’t optional with massive enterprise datasets.
Enterprises love bookkeeping, because they’re forced to keep records for compliance reasons, or because they’ve simply been doing the same work for many years and have accumulated a lot of documentation. Clearly, this contributes to the data size issue in that it can introduce noise, but it can also add a more aggressive form of noise: highly semantically similar records which, if unaccounted for, will become adversarial distractors to both your retrieval and generation systems. A good heuristic for whether this will be a problem is if data pertains to projects spanning long periods of time. All the enterprise examples below can be thought of as part of long-running projects (product development for a product, project management for a project, customer support for a customer) while the consumer examples are related to relatively shortlived events or objects. There are plenty of exceptions, but this is going to be a challenge more frequently in enterprises.
Enterprise Data
Startup/Consumer Data
If your project data has a lot of versions, entries, or copies, you should plan to address it from the beginning. Otherwise these versions can greatly increase retrieval noise and can lead to contradictory or untrue inputs to your generation system. The best courses of action are generally:
It’s best to avoid this challenge altogether by insisting on high-quality data rather than building complex passive version control or multi-signal re-ranking systems.
How many discrete forms of data does your application need to support? Data generated directly by individuals usually falls into our natural language modalities: text, audio, image, and video. Within those, we can look even deeper: text records may contain emails, code, documents, presentations, websites, etc… which might contain other forms of media themselves! Then there’s data about individuals and their behaviour, and about other entities (like products or events), which are often represented in structured formats like tables and graphs. The average enterprise will own a mixture of all of these, whereas a consumer often only consciously stores and processes a few. Think of the difference between a company’s data warehouse and your personal iCloud. In some enterprise areas (like federated search), you will need to deal with several modalities at once, while in others, you will focus on one at a time.
Enterprise Data
Another way of looking at this is that enterprises have myriad tiny categories of media, each containing many entries, whereas individual consumers tend to have fewer overall categories but (as we’ll see in the next section) greater variety within those categories. This property of enterprises actually turns out to be an advantage: the different types of content can help you scope your retrieval using the slicing technique described in the data size section and, even more importantly, scope your solution as narrowly as possible while still solving a user problem. As a general rule, only operate over the types of content that are necessary to address your use case. As much as possible, treat use cases that involve different modalities as different projects and solve them individually before combining them for a one-size-fitsall solution.
Though enterprises may have more different forms of content, all the examples of a certain kind are likely to be fairly similar. In structured data like graphs and tables, this is self-evident (because they were generated by a consistent business process), but why might it be the case with human-generated data like reports, presentations, and phone calls? The simplest reason is that enterprises and even entire industries have fairly reliable norms and procedures around communication, but those between consumers are more diverse. For example, sales phone calls tend to follow more reliable structures than phone calls between friends.
Enterprise Data
Startup/Consumer Data
Depending on where your project falls on the consumerenterprise spectrum, you may be able to make more assumptions about what the data looks like. If you’re building a product for internal use or to work with regulated documents, you have the highest certainty about the data structure that your system will need to handle. On the other hand, if you’re building a solution used by disparate enterprise customers, you may need to either build your solution flexibly enough to handle variable data schemas or perform discovery and system adaptation to each customer’s data. The parts of an LLM application in which differences may arise include pretty much everything: data ingestion, retrieval, and generation. For example:
The more you know about the data, the simpler and more reliable you can build a system to work with it. So use this knowledge when it’s available and design flexibly when it’s not.
Possibly the most mundane of the differences between the data in consumer and enterprise applications is who is allowed to access it. In consumer applications, this is typically straightforward: a user can access their data, but others can’t (except maybe an admin). However, in enterprises, this situation can become extremely complex, with numerous and frequently updating access groups for particular resources and different tiers of access. The stakes are often high, with employees needing access to certain data to perform their jobs but also needing access immediately revoked if they leave that role.
Enterprise Data
Consumer Data
Unfortunately, there’s no way to avoid a lot of engineering to implement access control properly. The best thing you can do for your project is to recognise this early and make sure you have the engineering expertise and client access necessary to figure it out. Definitely look to integrate with the data source’s identity provider if applicable, and look out for frameworks to help with the integration. Still, there are many decisions to be made about how your system handles different user groups, for example, in a system involving retrieval, will results be filtered before or after being retrieved (sometimes called early vs late-binding)?
I hope this article will raise some flags at the beginning of your enterprise LLM project that save you time later on, and help you form a de-biased intuition around LLM projects.