 Dr Tomislav Ilicic is a director at Accenture and leads the ASG Life Sciences Data & AI practice. His prior roles include Machine Learning Engineer, Data Scientist and Product Owner, and he holds a Bioinformatics degree from the University of Cambridge, UK. Tomi’s mission is to accelerate the AI transformation of life science companies by leveraging Accenture’s powerhouse, a C-level prioritised data strategy, and to encourage life science experts to adopt innovative tools.
Dr Tomislav Ilicic is a director at Accenture and leads the ASG Life Sciences Data & AI practice. His prior roles include Machine Learning Engineer, Data Scientist and Product Owner, and he holds a Bioinformatics degree from the University of Cambridge, UK. Tomi’s mission is to accelerate the AI transformation of life science companies by leveraging Accenture’s powerhouse, a C-level prioritised data strategy, and to encourage life science experts to adopt innovative tools.
In this post, Tomi explains how AI is proving invaluable to the pharma industry. AI-driven strategies are optimising efficiency and reducing costs across the entire pharma life cycle, from research to post-market surveillance. The use of AI in pharma, Tomi argues, offers a compelling example of how AI can revolutionise industries in 2024 and beyond:
In recent years, artificial intelligence (AI), particularly generative AI models like GPT-4, PaLM2 and LLaMA captured the interest of virtually any CEO and spiked expectations to transform entire industries. Within a year, ChatGPT became mainstream, and is already used in everyday tasks, making the entire world appreciate the immense potential and power of AI.
This global awakening to AI’s capabilities has set the stage for transformative changes across all industries, but probably the most disruptive will be within banking, insurance and pharmaceuticals. Big Pharma companies carry a ‘big bag’. This bag contains outdated IT systems, complex and bespoke data, strict regulations, millions of manually drafted reports, and increasing pressure not just to identify and produce new groundbreaking medicine but to do so cheaper and faster.
In seeking to serve society by enabling better patient outcomes, Big Pharma is embracing an AIenabled transformation (Figure 1). The AI-enabled transformation extends beyond a digital core but will bring about a total enterprise reinvention and enable data-driven insights to be gained by the wealth of bespoke data residing in the ‘big bag’. One key difference is this transformation will (sometimes) be enthusiastically driven both top-down and bottom-up, compared to introducing other tools, moving to the cloud and various other technology transformations.
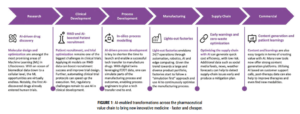
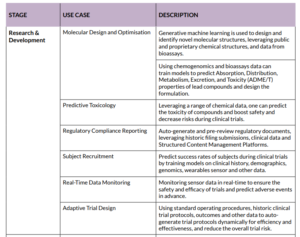
The pharmaceutical industry presents a compelling example of AI’s impact in 2024. Use cases across the pharma value chain demonstrate AI’s versatility and potential for innovation (Table 1). From drug discovery and patient diagnostics to supply chain optimisation and personalised medicine, AI is reshaping how the industry operates. These use cases not only enhance efficiency and reduce costs but also pioneer novel solutions to long-standing challenges, thereby creating substantial value for the industry and its consumers. Below is a high-level summary of the most common use cases across the pharma value chain.
Traditionally, drug discovery is done by utilising prior knowledge and laboratory experimentation to understand the underlying biological process of the diseases. This is done to identify new targets and perform high-throughput screenings (HTS) of large chemical libraries to select lead compounds and optimise those to satisfy a set of specific properties, such as solubility, toxicity, pharmacokinetics and other effects. It can take 3-5 years until a lead compound reaches Phase I of clinical trials. Although this approach led to many successful new drugs, it becomes increasingly difficult to find and develop innovative medicine faster and without exploding costs. Therefore, pharma companies have started to invest heavily in AI-driven drug discovery to boost their early-stage drug pipeline. Several biotech companies have already embraced AI at their core, and by doing so, they have managed to shorten the time it takes to reach clinical trials. AI-driven drug discovery can have many forms, and primarily aims to generate molecular designs, training on public and proprietary chemical data, omics, clinical trial outcomes, literature, and other third-party data. AlphaFold, for example, can predict the 3D folding of a protein to help understand its biological function, which used to be a very experiment-heavy and expensive exercise. Notably, there are advancements in leveraging GenAI to enable researchers with little computer science background to query their data or summarise publications using natural language. It is still unclear when the first AI-discovered drug will be approved, but the time is ripe, and pharma companies could develop innovative medicine for patients at a fraction of the current cost and time.
For drugs that have reached clinical trials, other challenges emerge, mostly around completing the clinical stages more quickly, cheaply, and with higher success ratios.
Pharmaceuticals struggle to reduce the time-tomarket for a new drug because clinical trials are very complex, often spanning multiple countries, relying on third parties such as clinical research organisations (intermediary between pharma and clinics), clinical sites and the struggle to find (and retain) the right subjects and execute the clinical protocol as intended. Pharma companies are turning to AI support, and several tools already exist: some are built on large language models to identify safety and efficacy information from clinical trial data or summarise them to ease the understanding of both doctors and subjects. Many efforts also go into predicting the eligibility of potential subjects and their risk of dropping out of the trial to increase the overall recruitment success. Drafting high-quality trial protocols enabling real-time monitoring using wearables is also a high-potential area to cut both time and costs and ultimately help market new treatments.
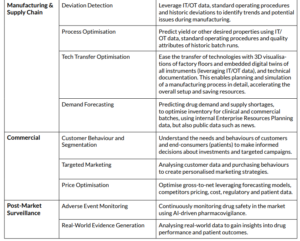
Not unique to the pharmaceutical industry, manufacturing and supply chains are rich in opportunities as they come with a lot of data and challenges. One of the major challenges is the trend towards personalised treatments (such as cell and gene therapies), which results in lower production volumes as they are more targeted. This is a big shift from socalled blockbuster drugs, which can be administered to millions of patients. That’s why manufacturing sites need to become more agile and modular to produce different drugs quickly without much effort. By training models on data from laboratory equipment, metadata of the batches, and technical documentation of the process, they can learn to predict the optimal parameters of new batches and make sure that the operators can generate more drug substance output, with less cost.
Adding a semantic layer on top of IT/OT data allows to simulate the manufacturing process, and to fine-tune a GenAI chatbot that can interact with instruments in real time. This can help the operators to quickly fix quality problems, and help them to plan a tech transfer from development to manufacturing, which is a very manual and difficult task.
With the advent of generative AI, many commercial functions such as branding, marketing and content production will be completely disrupted. This is mostly because of the strength of GenAI in being able to create new content, such as images and text. This is already affecting the many designer and marketing agencies that pharma companies are leveraging, as at least part of their work can be automated. A new trend is emerging, which is around creating country-specific product campaigns entirely driven by AI automate, including the Medical Legal Review. But, it can also be used to better understand the customer segments in the first place, and even make informed investment decisions about the early research pipeline. Further, clustering can be used to determine customer archetypes’ behaviour and optimise distribution channels.
Patients and subjects are monitored after they have received a treatment, and so-called real-world data is collected, which can be biomarkers such as blood pressure, heart rate, glucose levels, DNA tests and many others. Such data is already being used to identify patient factors that might trigger an adverse reaction and, in turn, can be used to predict adverse events for new drugs and ultimately make them safer for consumption. It can also be used for apps on wearable devices to trigger notifications to healthcare professionals, informing them about the potentially dangerous and life-threatening health status of the patient.
From drug discovery and patient diagnostics to supply chain optimisation and personalised medicine, AI is reshaping how the industry operates.

Although there is a wealth of use cases, each of them has one critical challenge: to generate measurable or observable value at scale. Scaling AI transcends mere technological expansion. It involves integrating AI into the core operational, strategic, and decisionmaking processes of an organisation. This scaling is not just a matter of deploying more algorithms or accumulating data. It’s about embedding AI into the fabric of the organisation, influencing everything from business strategies to employee workflows and customer interactions.
To effectively scale AI, organisations must consider a spectrum of aspects, not just technological. This includes developing a robust data infrastructure, fostering a culture of data literacy, ensuring responsible AI practices, and aligning AI initiatives with business objectives. It’s about creating an ecosystem where AI can thrive, supported by skilled personnel, clear governance, and strategic vision. Scaling AI, therefore, is as much about people and processes as it is about technology. Let’s talk about the six key factors that prevent scaling AI.
Data, the most critical element in the pharmaceutical industry, presents significant challenges due to its historical accumulation and complex system landscapes. Pharma companies have an ocean of data, but as you can imagine, finding the treasure in the ocean is a difficult task. The data ecosystem in the pharmaceutical industry is complex and rapidly evolving, driven by the increasing volume and variety of data from research, clinical trials, and real-world evidence (common data systems in Table 2). It can cover hundreds of different data systems, each with global and local instances and rollouts, and sometimes outdated technologies, which not only creates a complex web but also poses significant challenges to standardisation and modularity – a nightmare for IT, labour-intensive work for data engineers, value stagnation for data scientists and a box of pandora for executives. Many pharma companies are undergoing major transformations to simplify their system landscape, and continuous investments will be needed to identify the treasure and piles of gold while not drowning in data. It’s a paradox of not having enough data but also too much data. Companies didn’t do this on purpose but rather as a result of decades of changes and accumulation of systems. Removing what’s bad whilst ensuring that everything else runs is a very challenging task. It goes beyond technology and includes having the end-users follow FAIR (findability, accessibility, interoperability, and reusability) data principles and implementing them bottom-up everywhere and every time. Investments into modernising the IT and data landscape will yield high returns when coupled with the most strategic use cases/business problems (e.g. AI-driven drug discovery).
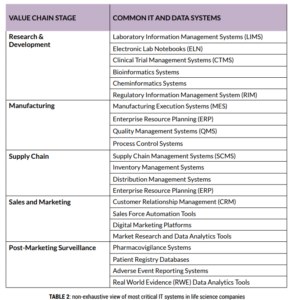
Another key challenge is to manage data integration from these disparate sources, ensuring data quality and compliance with stringent regulatory standards and addressing data privacy concerns. The proliferation of diverse data platforms creates another layer of complexity. This multiplicity not only fragments the data landscape, creating silos and complicating the integration process, but also imposes significant costs and maintenance burdens. The key to navigating this complexity lies in adopting a holistic data management strategy. This strategy should prioritise robust data integration tools capable of harmonising disparate data sources, thereby ensuring data integrity and facilitating comprehensive analysis. Additionally, a shift towards cloud-based unified platforms could offer more seamless integration and scalability. It’s essential to involve data scientists and IT experts in this process, leveraging their insights for optimal platform integration and utilisation. Regular audits and a focus on scalable architectures can further streamline operations. Ultimately, the goal is to transform this multitude of individual platforms from a fragmented puzzle into a coherent, efficient, and insightful data ecosystem, driving informed decision-making and innovation in the pharmaceutical sector.
Just because data sits in a data lake, it doesn’t mean that it can be used to solve business problems. Data engineers face the monumental task of creating ‘consumable’ or business-relevant data, by cleansing, normalising and transforming data, and describing the context found from the tangled web of platforms and raw sources. To do so more systematically, data mesh established itself as a popular concept, comprising a decentralised data architecture that treats data as a product, managed by domain-oriented teams who own and operate their data independently, while adhering to common standards and governance. It’s like a welldocumented storage of goods grouped together (e.g. parts of a car engine). But even if a large and wellmaintained storage of data products does exist, solving complex problems (e.g. building a car) requires knowing the relationship between data points (e.g. what parts are required to build the car). To do so, a so-called semantic layer can be added on top, which allows models to learn relationships between data products and create accurate responses/predictions. This makes the difference between AI being able to generate emails, versus regulatory filings containing confidential and complex information. Scaling the creation of business-relevant data products and a semantic layer requires a strong emphasis on involving key SMEs who can help the data teams in identifying and understanding the raw data. Their involvement is critical, yet constrained by their own priorities and workload. With the right team, clear focus and a strong data platform in place, one can implement data products in a factory approach, creating large amounts of high-quality data at a fast pace.
Hundreds of new foundation models have emerged, most of which are specialised for specific use cases. Assuming data products are available, it now requires a highly parallelised evaluation approach to pick out the bestperforming model for a specific use case. This is where MLOps become another critical component of the endto-end architecture of data analytics at scale. Choosing one MLOps platform and training data scientists and engineers on it can truly accelerate building, deploying, and maintaining models, often referred to as ‘industrialised’ models. Such tools also help to be on top of costs and consumption, which for large organisations can become substantial. Pick one MLOps platform and train data scientists and engineers in using it, to truly build models at scale.
Many organisations focus on all the technical aspects above and invest a lot of money into platforms, data curation and models. However, one important aspect often gets neglected: the involvement of end-users very early on and having a detailed understanding of the most valuable projects, capabilities and the estimated impact of the AI solution. So rather than starting with development right away, it can help to take a step back and think critically about what use cases (or groups of use cases, or capabilities) will provide the most value. Many clients have a long backlog of use cases (sometimes in the hundreds) they want to implement, but without a clear focus one can run into the danger of getting stuck in PoC land. There, it can help to estimate ROI and the technical feasibility of each use case early on, in order to better prioritise. In addition, holding design-thinking workshops with a few end-users to create paper and Figma prototypes can speed development massively and create a first solid product fast. This approach is similar to building a house, where seeing the final 3D design helps with planning and optimising the building blocks within. Once it’s clear what needs to be built, it’s much easier to navigate the complex web mentioned above. This methodology ensures that the development of AI models and data products is aligned with the most critical use cases and end-user needs, ensuring a return on investments, and hence moving away from PoC land.
Finally, an important puzzle piece to scale AI in organisations is not only the technology but us humans. It starts with employees entering data in a standardised way, helping data teams to resolve issues, and lastly, defining how the solution can be used effectively day-to-day and training their co-workers to adopt it. Doing this will move the needle. Whoever performs a core-business job, such as researcher, clinician, manufacturing operator, or regulatory/quality expert, and is interested in AI, should invest time to work with data teams. Although it will take time for the two worlds to speak one common language, over time, it can become a win-win situation for both worlds, and will moon-shoot careers once high-quality data products have been built and are used to create measurable value and impact across the organisation.
In synthesising the future of AI in pharmaceuticals, scaling is the pivotal chapter. It’s not merely about enlarging the role of AI but fundamentally transforming how we think about and employ this technology. Scaling AI transcends the technical – it’s about weaving intelligent algorithms into the very DNA of pharmaceutical operations and decision-making frameworks. It means moving beyond pilot programs and isolated successes to a state where AI-enabled insights and automation are as ubiquitous and essential as electricity in the industrial age.
To truly scale AI is to embed it into the day-to-day rhythm of the pharma industry, ensuring that from the laboratory bench to the patient’s bedside, every process is enhanced by data-driven decision-making. It’s the seamless convergence of AI with the core strategic goals of the industry – accelerating drug discovery, personalising patient care, optimising supply chains, and ensuring the safety and efficacy of medications in real-world scenarios.
As we advance, scaling AI will be the barometer of innovation and the catalyst for a new paradigm in healthcare. It promises a future where treatments are not only discovered and developed faster but are also more in tune with the needs of diverse populations. In this future, AI will not just be an adjunct but a fundamental engine of growth, driving the industry towards unprecedented efficiency and effectiveness in serving the global community. This is the essence of scaling AI in pharmaceuticals: it’s a journey of transforming potential into real-world impact, ensuring that the power of AI fully realises its promise to revolutionise healthcare for all.